Assignment #3 - Flow Fields
GPR440 Advanced AI
[ 3.7.21 ]
| Made With | Languages |
|---|---|
| Unity3D Rider |
C# |
Overview
The goal of this project was to implement flow field pathfinding. Similarly to the last one, I tried to integrate this one with the last. To do this, all I really did was switch out the seek steering with flow steering and added a key binding so I could clear pathing so the boids didn't constantly path towards the target point.
Flow fields are a really cool way to handle pathing for multiple units for a few reasons:
- Flow fields don't care how many units there are
- Flow fields don't care where the units are (provided they can reach the target node)
- Flow fields will only process nodes that are accessible to the target node
So, while maybe not ideal if you only have a few agents active at any given time, but if you do have a lot of agents, flow fields allows you to calculate a path to the target node for every agent with one function call. It does this by essentially finding the path to the target node from every other reachable node. It then acts as a record so that no matter where an agent is, it can get the direction it needs to go next from the flow field.
It's advantage over other pathfinding like A*, is that with those you have to calculate the entire path for every single unit. If you have many units, you then have to call your A* algorithm many times, and if the agents are in similar positions, you may be processing the same nodes to produce almost the same path many times. A flow field only needs to be calculated once, eliminating any unnecessary re-processing of nodes
The Basic Setup
The setup for a flow field is actually pretty straightforward. You only need some kind of 'node' or 'cell' class to make up your grid, and then an actual grid to hold the nodes and do the required processing.
class Node
{
private Vector3 _flowDir;
private int _weight;
private float _distance;
// getters and setters
// constructor(s)
public void UpdateWeight()
}Node
For the node, the basic data you need is the direction an agent should move when in that cell, it's weight (higher weight signals 'tougher' terrain) and distance (from the target node). The last two are what's used to calculate the flow direction. I also include the world position and a reference to the flow field it is contained in.
You also need the constructor and any getters and setters you may need, then i also have an update weight function. In my implementation, the node's weight is based on how many colliders are within its bounds (using an OverlapBox).
class FlowField
{
public Vector3Int dimensions;
public float spacing = 2f;
public int batchSize = 25;
private Node[] _map;
private Vector3 _target, _centerOffset, _halfDims;
private int _numNodes;
private float _worldToMap;
}Flow Field
For the flow field, the basic needs are its dimensions, the size of the nodes, the target location and the array that holds all of the nodes in the flow field. I have my implementation process nodes in batches to lessen the impact on framerate, and I also have offset and conversion variables for centering the flow field in world space.
From there, you just need the actual flow field functionality along with other helper functions to help facilitate the whole process.
Calculating the Flow Field
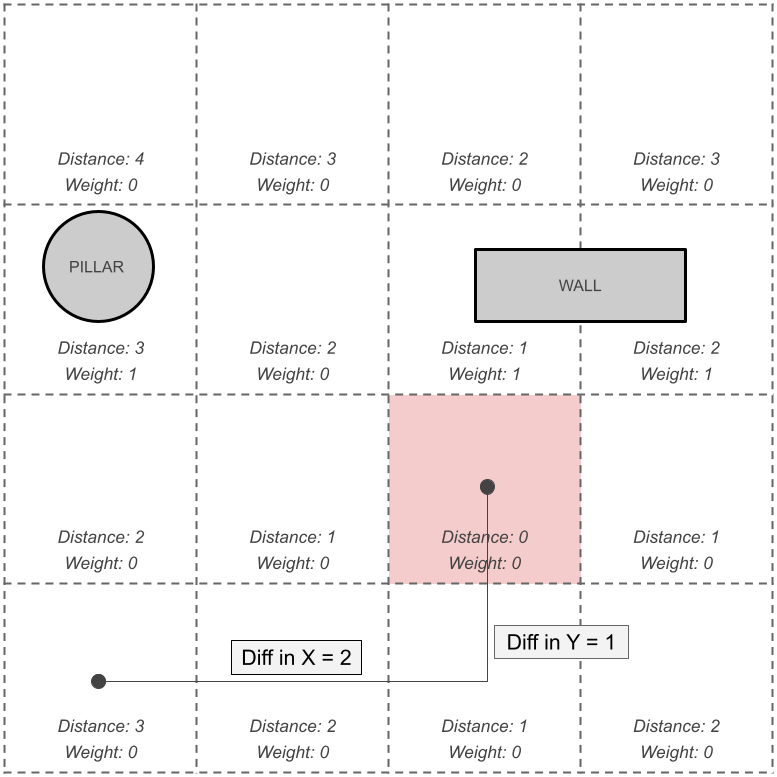
As I said before, calculating the flow field, at least conceptually, is not too difficult. Basically, you start with your target node, then move outwards using an algorithm like Dijkstra's updating the distance from the target as you go. To do this, you maintain an open and a closed list, or, nodes that are next to be processed (open) and nodes that have already been processed (closed).
The target node is the 'seed' for the open list and the first node that you process. For the target node, you set the distance to 0. Then, you continue to populate the open list by adding the neighboring nodes to it and moving the node you just processed to the closed list. To process a node, you can calculate distance by either setting a neighbor's distance to 1 + the current node's distance, or use Manhattan distance: | tx - cx | + |ty - cy | where t is the target node and c is the current node.
// keep going until no more new neighbors to process
while (openList.Count > 0)
{
// get node to process from front of list
Node curr = openList[0];
// move from open to closed
openList.RemoveAt(0);
closedList.Add(curr);
// get the connections
List<Node> neighbors = GetNeighborsOf(curr);
// check all the connections
foreach (Node neighbor in neighbors)
{
// first check if in either list yet
if (InList(ref openList, neighbor) == -1 &&
InList(ref closedList, neighbor) == -1)
{
// if it hasn't been touched then add to open
openList.Add(neighbor);
neighbor.Distance = curr.Distance + 1f;
}
}
}// Find flow direction for every processed node
// (comes after the while loop)
foreach (Node node in closedList)
{
// get the node's neighbors
Node[] neighbors = GetNeighborsOf(node);
// lowest total cost of the neighbors
float lowestCost = neighbors[0].Distance;
// index of the neighbor with that cost
int lowIn = 0;
// cycle thru the rest of the neighbors to
// check if a lower cost option is available
for (int i = 1; i < neighbors.Count; i++)
{
// if the neighbor's cost is less than the lowest
if (neighbors[i].Distance + neighbors[i].Weight < lowestDist)
{
// then log it as new lowest
lowIn = i;
lowestCost = neighbors[i].Distance + neighbors[i].Weight;
}
}
// make current node's direction face the closest one
node.FlowDir = (neighbors[lowIn].Position - node.Position).normalized;
}Making it Interruptible
A smaller quality of life thing I implemented was making the flow field calculation interruptible. While you could likely calculate a smaller flow field fairly quickly (especially if you were able to optimize the process more, and were not also rendering it), large flow fields can cause a brief stutter as you try to process hundreds and hundreds of nodes. This necessitates either reducing overall runtime or spreading it out over multiple frames, to prevent the calculations to compromise the user experience.
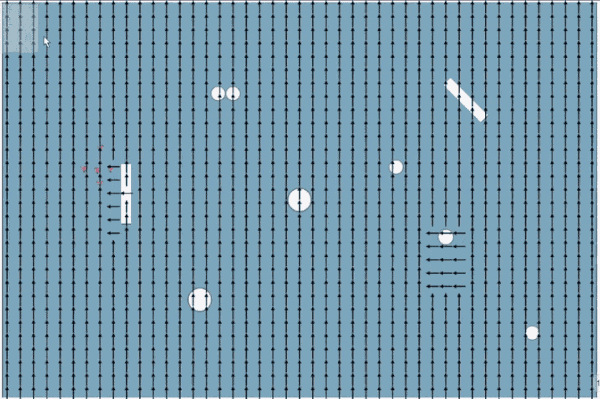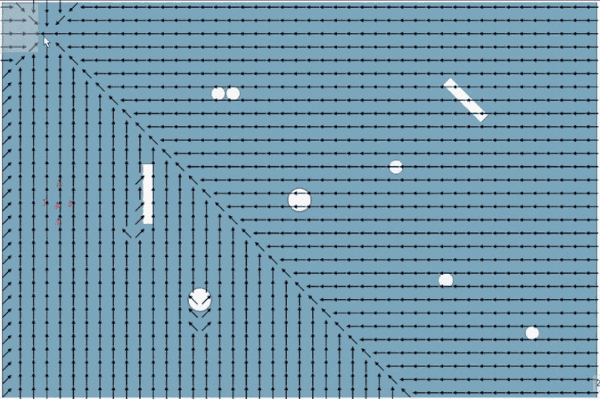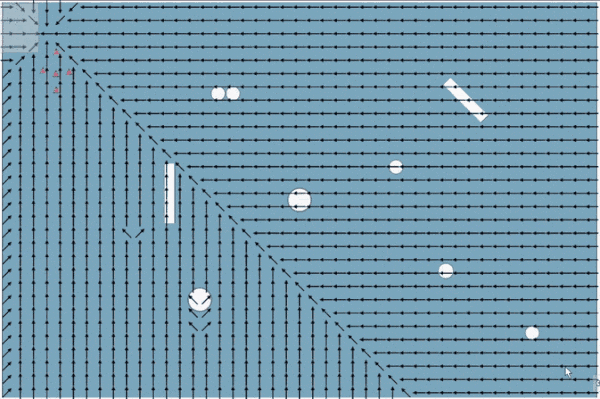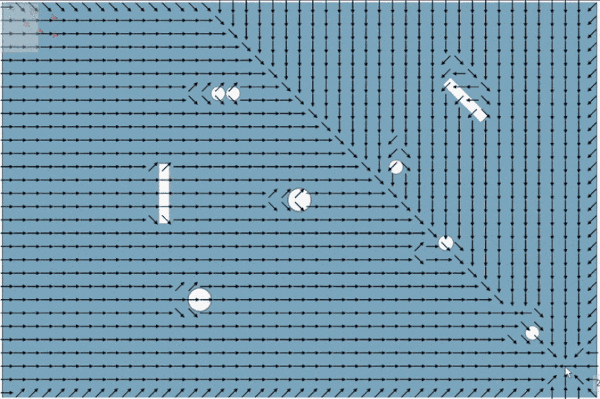
A 45x30 grid processing 3 nodes/frame
To do this, I have a 'batch size' variable for the flow field that caps the number of nodes the flow field can calculate in one frame. Then, I also introduced a processedList array to hold nodes that have already been updated, so I don't accidentally re-add them to the open/closed list (causing potentially an infinite loop or just re-processing a bunch of nodes).
From there, you would replace the normal while with a for loop and change the lines where you check if the neighbor is in a list already to include a check for if it is in the processedList array. Then, when you process the closed list, move those nodes from the closed list to the processed list and you should be golden.
While this may look slow and/or clunky in the gif, you shouldn't worry for 2 reasons:
- You would likely calculate the grid much faster by:
- Use a courser grid (less nodes), and
- A much higher processing rate (easily 50+ nodes/frame)
- The user likely won't notice the grid calculation even if it does take a few frames because:
- The agents closest to target node get updated directions first, and
- The agents farthest often wont see massive changes in direction, and
- You normally don't show a flow field to an actual user